
by Theresa Miller | Jan 22, 2023 | Microsoft Technology, Theresa Miller
Did you know that there are entities likely spoofing your business identity without your knowledge? These are messages that are being sent out “pretending” to be from your company when they didn’t originate from within your organization. How can a company begin to...

by Theresa Miller | Nov 29, 2022 | Goliath Technologies, Monitoring Tools, Strategy, Theresa Miller
Major vendors have been doubling down on their investment in Chromebooks, and that effort has paid off — they’ve consistently seen strong returns thanks to the platform’s wide adoption globally. Source (2021). Additionally, as we consider school system...

by Gina Rosenthal | Nov 22, 2022 | Gina Rosenthal, Security
Disclosure: I was an invited speaker for Teleport Connect and they paid my expenses. However, they have not seen or approved this blog post in advance. I live-blogged the conference here. I attended Teleport Connect 2022 conference in San Francisco earlier this month....

by Gina Rosenthal | Nov 10, 2022 | Melissa Palmer, Ransomware, Security
When we talk about security threats out there, ransomware is sadly top of mind these days. You know what else we hear a lot about? Bot nets. You know what’s worse than just bots or ransomware? Combining the two, which has begun to happen, believe it or not....
by Gina Rosenthal | Oct 25, 2022 | Cloud, Gina Rosenthal
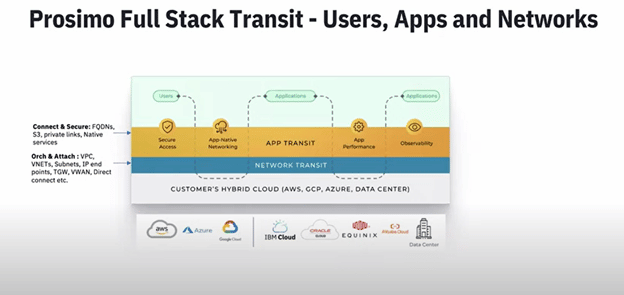
I was at Cloud Field Day 15 and was very interested in the presentations by Prosimo. They are a three-year-old startup who have only been out of stealth for about 16 months. They have a platform that solves the complexity of multi-cloud networking. I am not much of a...

by Gina Rosenthal | Oct 18, 2022 | Melissa Palmer, Ransomware, Security
I have a funny story about ransomware. You see, a long time ago (well not that long in real time, but very long ago in ransomware time) I had a lab in the public cloud that got hit by ransomware. My best guess? Remote Desktop Protocol (RDP), also known as...

by Gina Rosenthal | Sep 27, 2022 | Cloud, Gina Rosenthal, Monitoring Tools
I was fortunate to be a delegate during Cloud Field Day 15. Many discussions were had about the definition of cloud, multi-cloud, and even supercloud. We heard from six different vendor who provide solutions to almost every facet of cloud. I really enjoyed learning...
by Gina Rosenthal | Sep 15, 2022 | Melissa Palmer, Ransomware, Security
Each and every day there is a new ransomware attack. Well, more like there are many many ransomware attacks each and every dayRecently, Lorenz Ransomware has been all over the news. While they have been around since 2020, we have heard new things about them over the...
by Gina Rosenthal | Aug 23, 2022 | Cloud, Gina Rosenthal
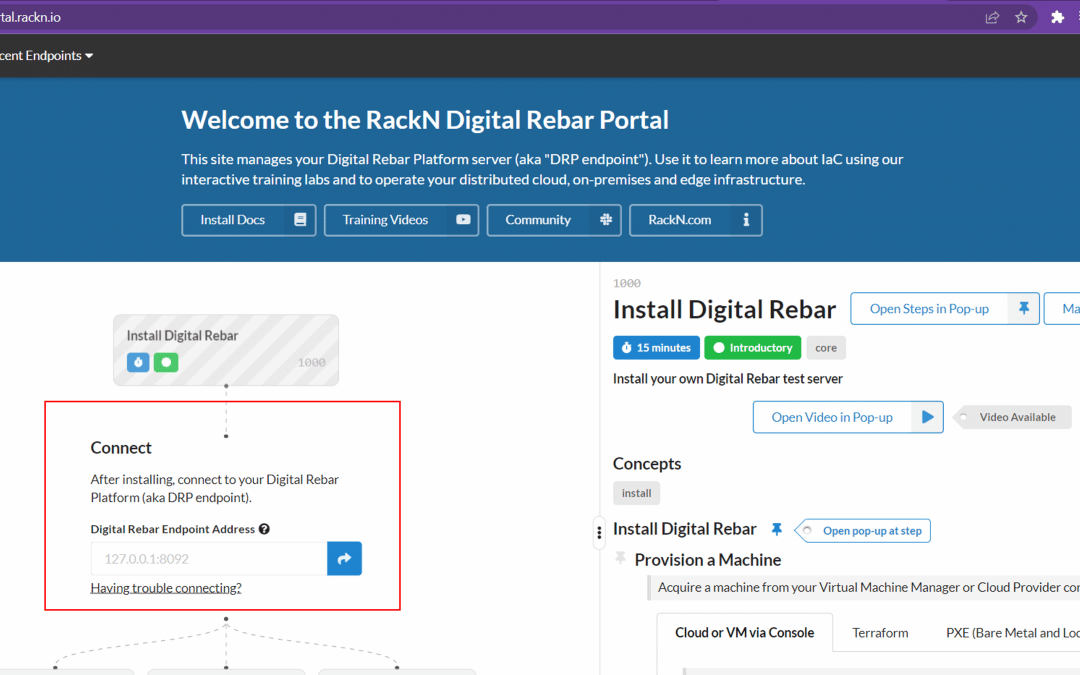
If you’re a traditional admin you probably know that you need to learn how to manage automation, and that means learning about Infrastructure as Code (IaC). But where should you even start? RackN has a platform that automates IaC, so maybe doing their Digital...

by Gina Rosenthal | Aug 9, 2022 | Melissa Palmer, Ransomware, Security
Today for the latest in my ransomware series I thought it would be fun to take a look at a more interesting ransomware group with some history. REvil ransomware is an interesting one, since they were actually tracked down, members caught, and “disbanded”....