
If your organization is building AI applications, you’ll be responsible for architecting AI infrastructure. Last week we talked about AI-enhanced services, but those are services using AI to make a product smarter. Those folks are also building environments to support building their AI enhanced products. If you’re not familiar with what it takes to “build AI”, this post is the primer for you.
Considerations for AI Infrastructure
I wrote this post (with my colleague Don Sullivan) about machine learning infrastructure a few years ago when I worked for VMware. Of course, machine learning and deep learning are components of an AI application. I think for the operations folks who are responsible for the AI infrastructure, it’s important to understand the required components. Of course, just as with any other architecture, you have to understand how the applications are designed.
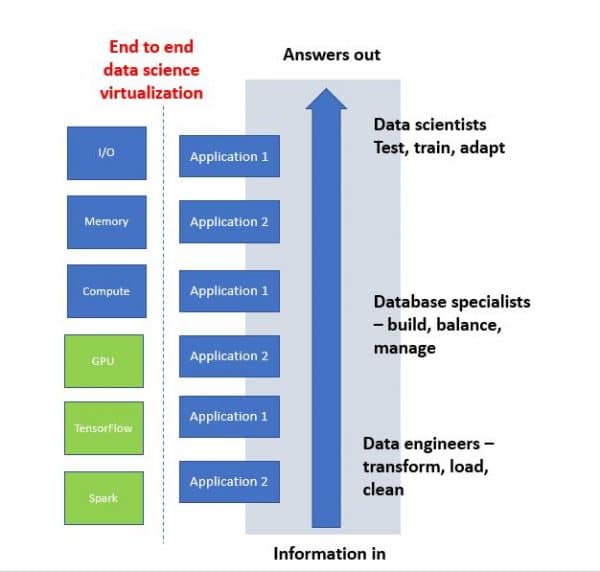
This image from the blog post show the architectural elements are on the left, and the data scientists responsibilities are on the right. AI (and machine learning or deep learning) are applications, or workloads. Operations people understand workloads. These workloads are different than what we’re used to, and that’s because the architectural building blocks are also different. This is pretty exciting, because the future is here now! I was able to see this as a delegate on AI Field Day. In addition to the AI-enhanced products I wrote about in my previous post, we heard from AI Infrastructure vendors.
Refresh your Vocabulary
To understand AI architecture you probably need to do a bit of research on the vocabulary of AI. For example, BrainChip manufactures a neural system on a chip. It does neuromorphic processing – event-based processing that only kicks in after a specified event transpires. One use case would be object classification in an Edge environment, perhaps identifying license plates or even people.
Open Source is a Choice
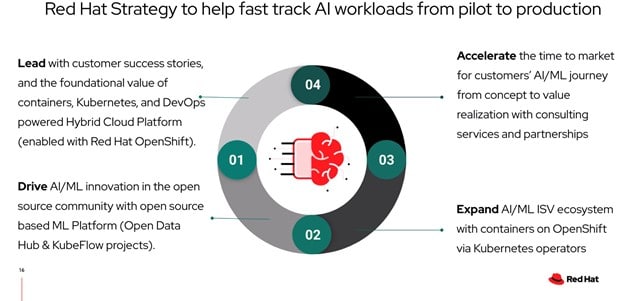
RedHat has open source covered with their presentation on OpenShift. Of course, Ceph got a few mentions. This was a huge topic to cover, as it is most of the time with infrastructure that can be used for so many things. But this slide shows that their focus is on customers who want to use open source resources to build their AI infrastructure.
AI Infrastructure Powered by Intel
It’s hard to talk about AI infrastructure without talking about vendors that manufacture the powerful chips that make AI possible. Intel is one of those vendors, and this slide shows the breadth of how their products can be used in an AI infrastructure.
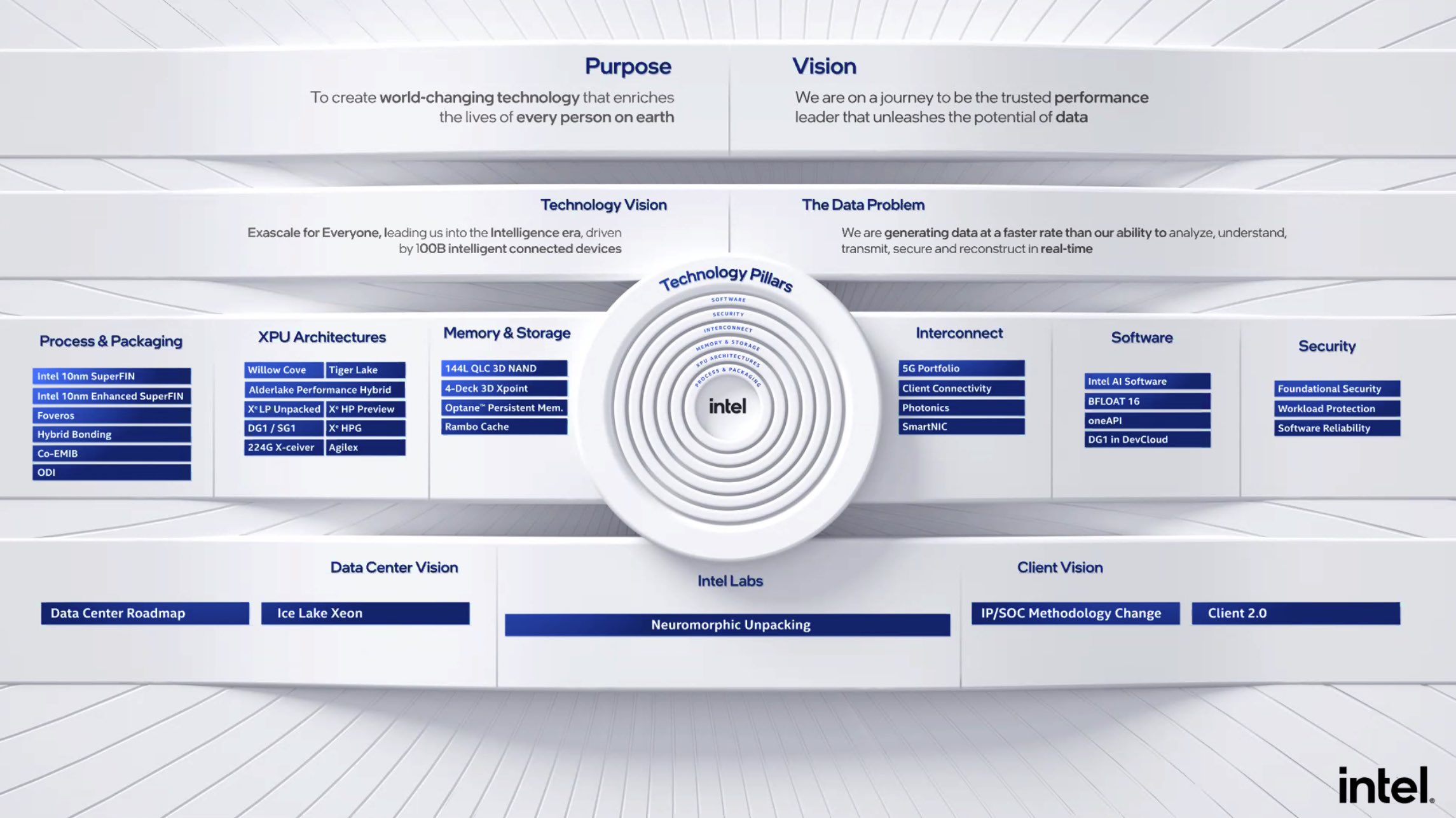
One thing I found interesting was Intel’s oneAPI initiative. The goal is the make it so any architecture (GPU, CPU, FPGA, etc.) will work with any API. This will prevent lock-in with languages (for example CUDA). I think this is a great initiative, and hope the industry adopts it. They also have a big data platform called Analytics Zoo that you can check it. It also seems pretty cool (github link).
I also enjoyed Jason Dai’s comment: “Data scientists don’t want to think about a distributed system”. This goes back to the idea that the algorithms data scientists work with are just workloads. That helped me understand the role operations folk play in AI. We create the best, most performant algorithms for these workloads. For most of us, that may mean we need to spend a little time understanding the products of the AI infrastructure vendors.
Big Memory Computing
The MemVerge presentation was sponsored by Intel. Memverge created “Big Memory” technology that massively scales out DRAM and Persistent Memory. Their use case really highlights how architectures are changing. This is from the MemVerge website:
We live in an age of data. Driven by AI, machine learning, IOT, and big data analytics, more and more data are being created, and these data need to be processed at a faster and faster speed. Today’s storage systems cannot keep up with the capacity and performance requirements from real-time data collection and analytics. …The advent of Persistent Memory technologies are setting the stage for a new era of Big Memory Computing: an era where applications of any size can forgo traditional storage systems in favor of large pools of persistent memory. Hardware alone is not sufficient to usher in this new era. Software innovations are required to make Big Memory enterprise-class.
So we have the hardware to create AI applications, but we need software that helps the applications interact properly with the infrastructure. This presentation was really good, hearing straight from the vendor really helps cement the concepts.
Vast Innovates Storage Access
The Vast Data presentation was also sponsored by Intel. I like the way Vast Data describes the AI architecture problem facing traditional ops people:
Customers need to keep GPU servers fed with more bandwidth than what a NAS can deliver, causing them to think that complex parallel file systems are the only answer. On the other hand, file accesses are small and random in nature, making AI the killer use case for flash storage – but parallel file systems and burst buffers were never designed for providing random read access to petabytes of flash.
Vast is one of the companies building for the new types of applications (like AI). Once you understand that an AI app needs to lots of bandwidth for lots and lots of small and random file access reads, you begin to see how traditional NAS and SAN just won’t be able to handle things. Vast built a platform that uses all network interfaces, but distributes the load across the interfaces. They added support for port failover (that they also contributed upstream) and use RDMA. Vast went through the problem and their solution in this video.
Real Talk
Until very recently, the only people building AI infrastructures were sysadmins that support things like rocket science and DNA research. Now there are plenty of vendors working on providing solutions that make the architectural components more available to enterprise customers.
AI applications are just workloads, and workloads run on architectures. I think we’ll see a real need for storage and hardware people to step up and learn all of the new ways to build a distributed infrastructure that can support AI applications.